Debugging and Profiling
While using the hi-ml toolbox modules, you might encounter some errors that require running the code step by step in order to track down the source of these errors. Here are some guidelines to help you debug and/or profile hi-ml deep learning training pipelines.
Debugging within VS Code
VS code has a great Debugging Support for many programming languages. Make sure to install and enable the Python Extension for VS Code to debug hi-ml toolbox modules built in Python.
Debugging configs
The hi-ml repository is organised in Multi-root workspaces to account for environment differences among the modules and offer flexibility to configure each module seperatly.
We provide a set of example debugging configs for each of hi-ml module:
VS Code restricts debugging to user-written code only by default. If you want to step through external code and
standard libraries functions, set "justMyCode": false inside the debugging config block in the launch.json file.
In particular, if you would like to debug the current file while breaking through external libraries, navigate to
himl-projects.code-workspace in the repo root and edit the “launch” block as follows:
"launch": {
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false
},
],
}
PyTorch Lightning flags for debugging and quick runs
The hi-ml toolbox is built upon PyTorch Lightning (PL) to help you build scalable deep learning models for healthcare and life sciences. Refer to Running ML Experiments with hi-ml for detailed instructions on how to build scalable pipelines within hi-ml.
Whether you’re building a brand new model, or extending an existing one, you might want to make sure that your code runs as expected locally before submitting a job to AzureML. hi-ml supports a set of debugging flags that triggers PyTorch Lightning Trainer arguments to help you detect any potential errors or bugs at early stage.
These are available as part of the TrainerParams and can be used as extra command line arguments with the hi-ml runner.
pl_fast_dev_run: If set ton, runs the pipeline for onlynbatch(es) of train, val and test for only a single epoch. Additionally this flag disables all callbacks and hyperparameters serialization which makes the debugging process very quick. This must be used for debugging purposes only.pl_limit_train_batches: Limits the training dataset to the given number of batchesn.pl_limit_val_batches: Limits the validation dataset to the given number of batchesn.pl_limit_train_batches: Limits the test dataset to the given number of batchesn.
In general, it is very useful to run the following two steps as part of the developement cycle:
Make sure all training, validation and test loops complete properly by running the pipeline with a smaller batch size and
pl_fast_dev_runargument. Add the following to the hi-ml runner command line:
--bach-size=2 --pl-fast-dev-run=4
Make sure the whole pipeline runs properly end to end, including checkpoints callbacks and hyperparameter serialization by running it with a smaller batch size once again while limiting train/val/test batches for few epochs. Add the following arguments to the hi-ml runner command line:
--bach-size=2 --pl-limit-train-batches=4 --pl-limit-val-batches=4 --pl-limit-test-batches=4 --max_epochs=4
Note: Under the hood, setting pl-fast-dev-run=n overrides
pl-limit-train-batches=n, pl-limit-val-batches=n, pl-limit-train-batches=n, max_epochs=1 and disables all
callbacks. Please keep in mind that all the above is useful for efficient and quick debugging purposes only.
Profiling Machine Learning Pipelines
PyTorch Lightning supports a set of built-in
profilers that help you identify
bottlenecks in your code during training, testing and inference. You can trigger code profiling through the command line
argument --pl_profiler that you can set to either
simple,
advanced, or
pytorch.
The profiler outputs will be saved in a subfolder profiler inside the outputs folder of the run. Give it a try by
adding the following arguments to the hi-ml runner:
--max_epochs=4 --pl-profiler=pytorch
Interpret PyTorch Profiling outputs via Tensorboard
PyTorch Profiler can effectively be interpreted via
TensorBoard dashbord interface that is integrated in VS
Code as part of the Python
extension. Once you have the outputs of the PyTorch Profiler in outputs/YYYY-MM-DDTHHmmssZ_YourCustomContainer/pytorch_profiler, you can
open the TensorBoard Profiler plugin by launching the Command Palette using the keyboard shortcut CTRL + SHIFT + P (CMD
+ SHIFT + P on a Mac) and typing the “Launch TensorBoard” command.

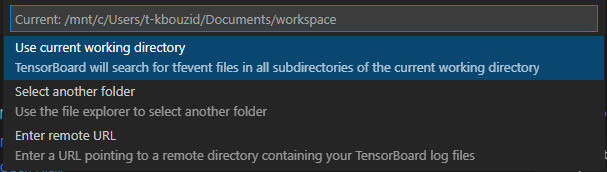
Next, you will be asked to select the path where the profiler traces are saved. Select another folder and navigate to outputs/YYYY-MM-DDTHHmmssZ_YourCustomContainer/pytorch_profiler.
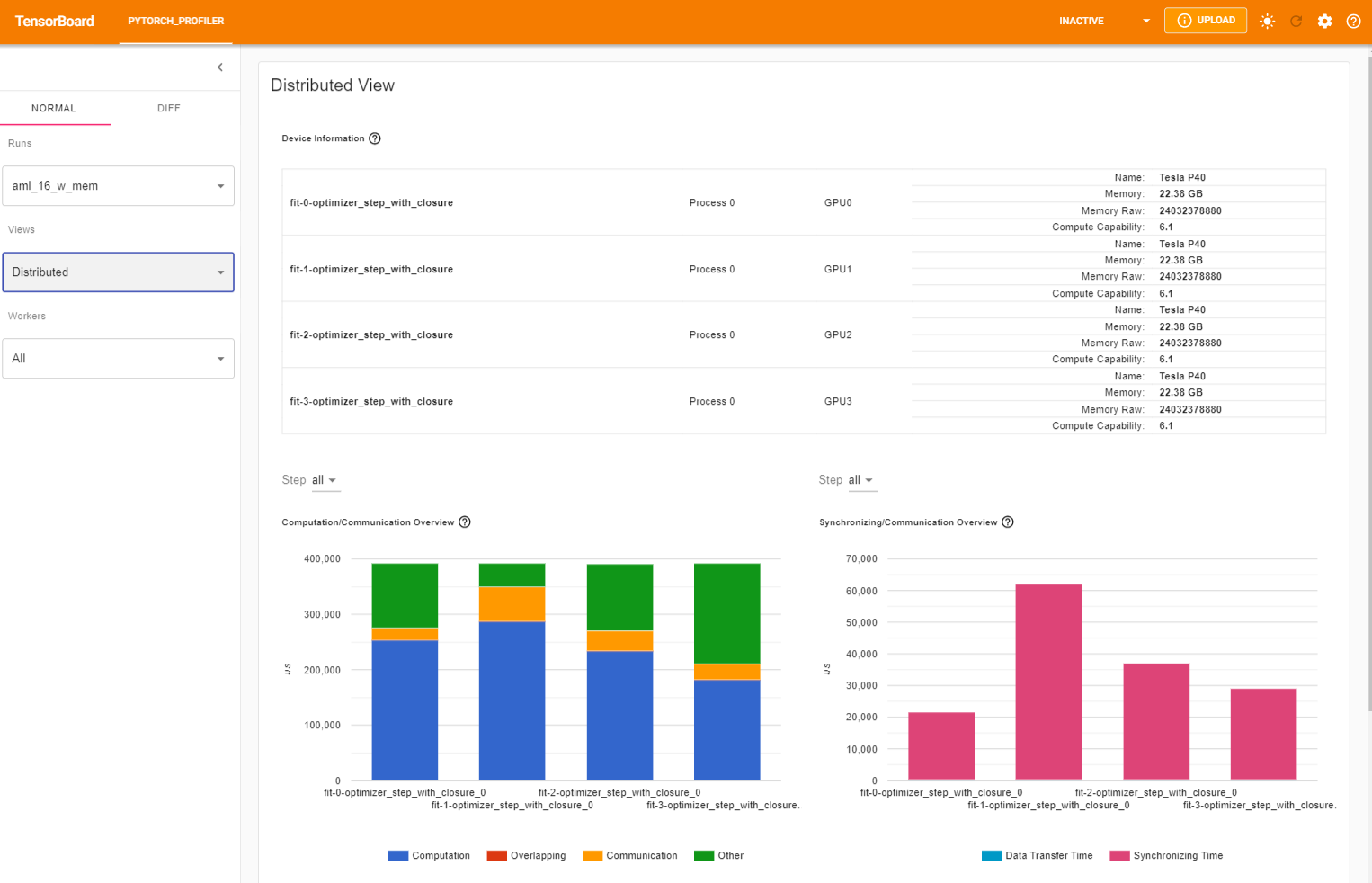
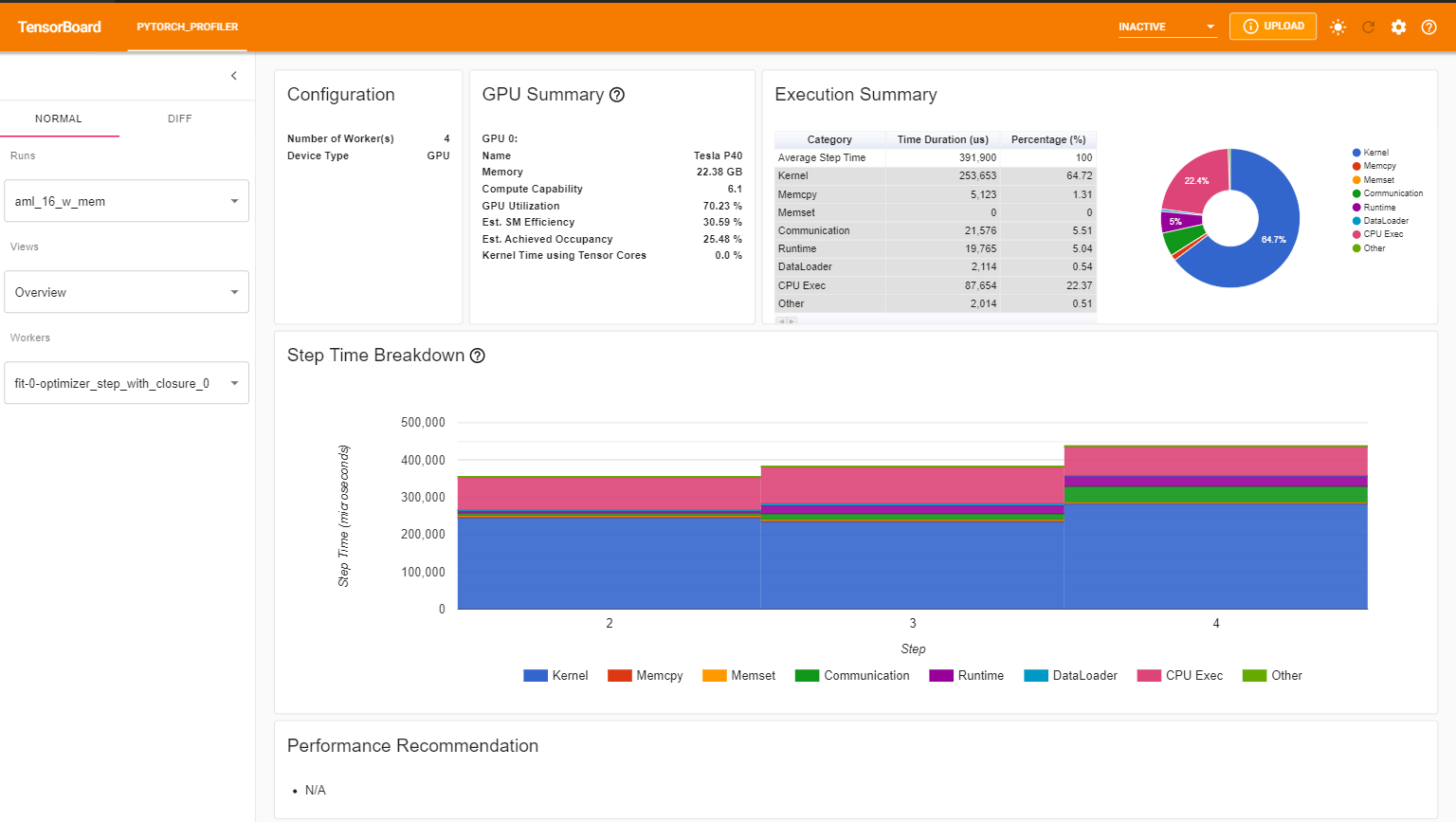
You can see Profiler plugin page as shown below. The overview shows a high-level summary of model performance.
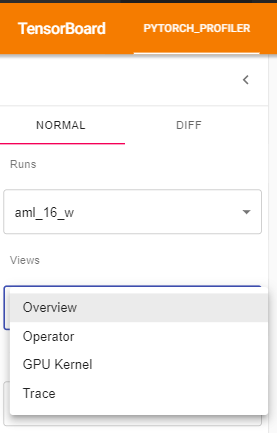
You can change the view page in the left dropdown list.
The operator view displays the performance of every PyTorch operator that is executed either on the host or device.
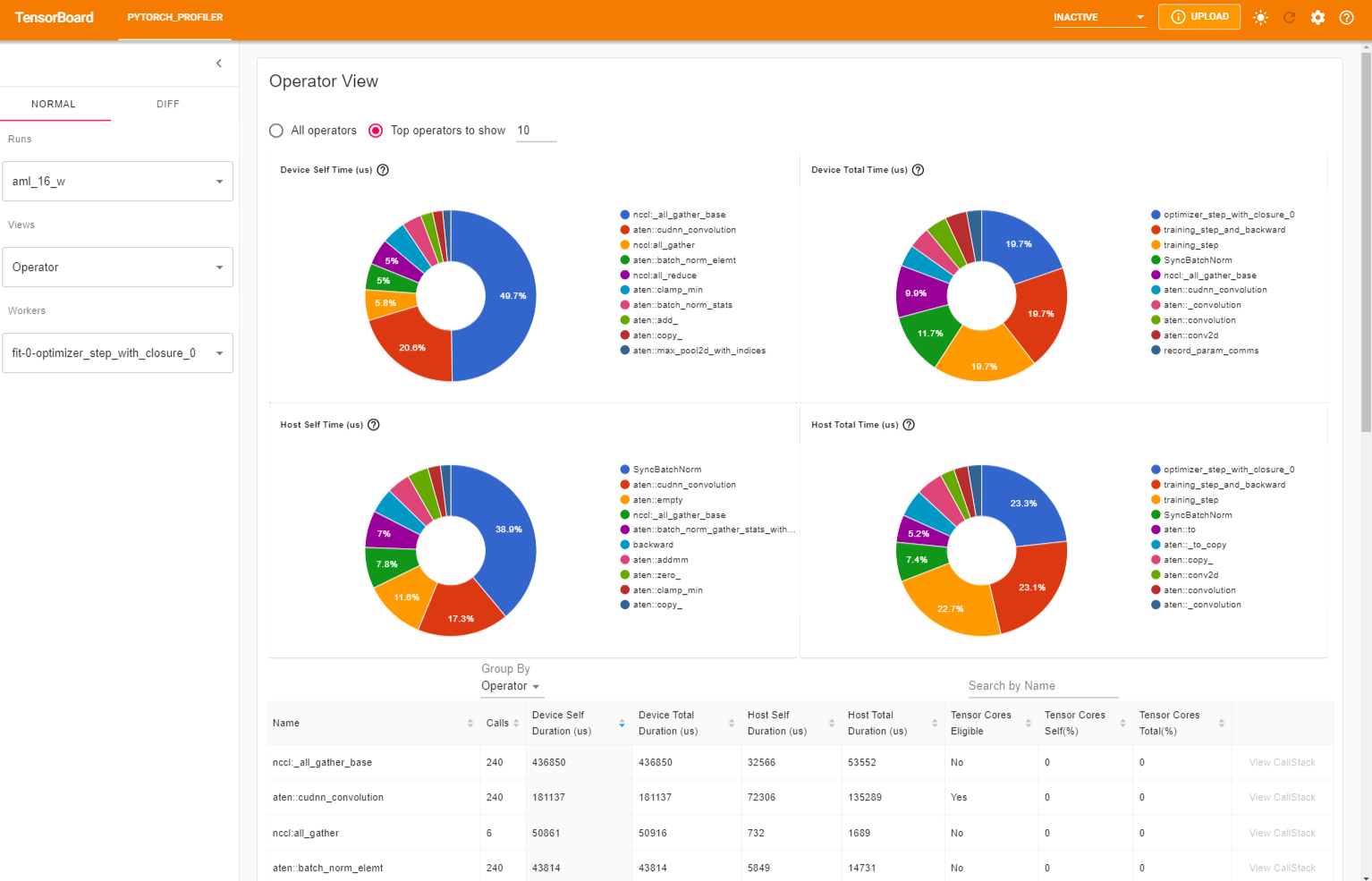
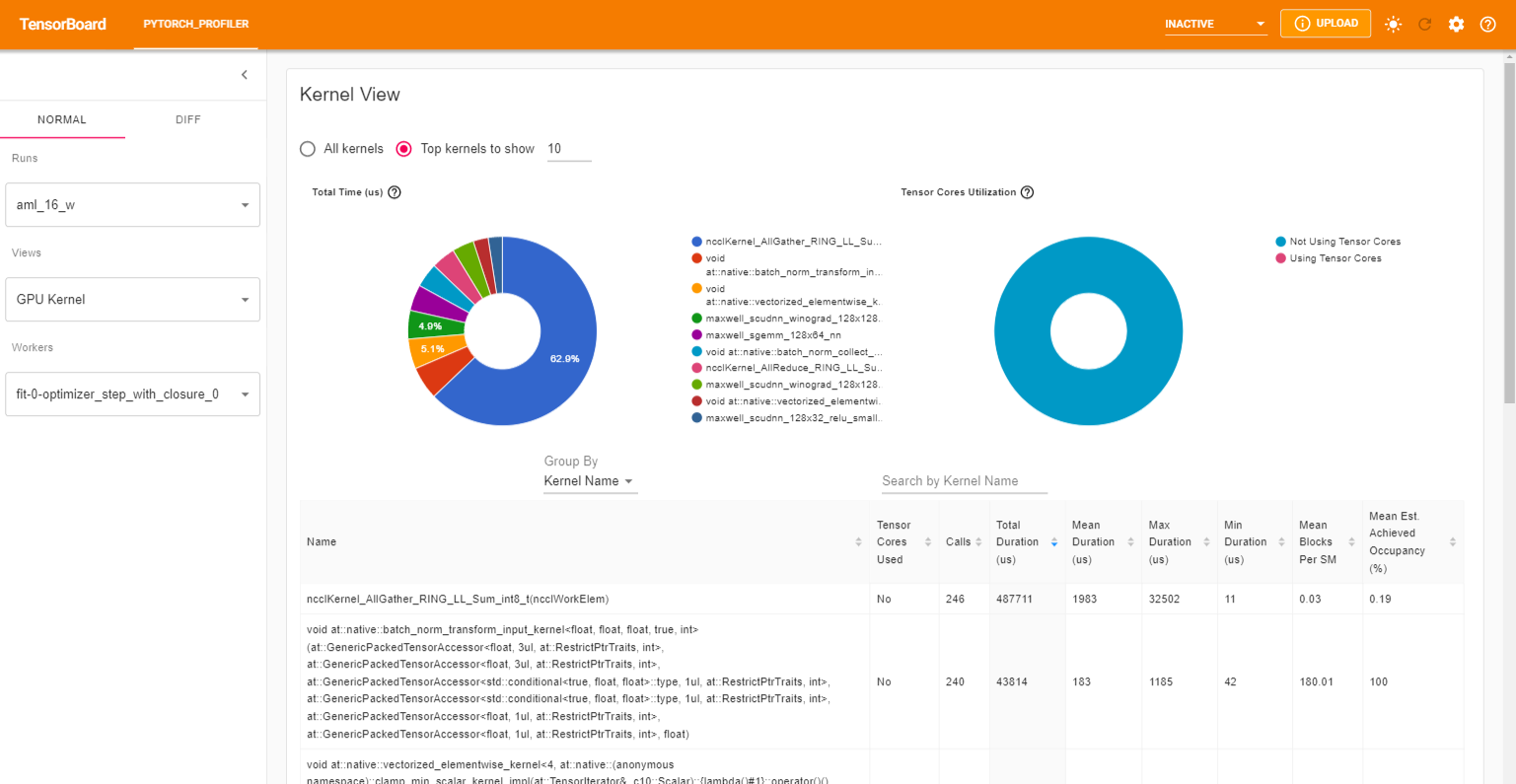
The GPU Kernel panel shows the GPU configuration, GPU usage and Tensor Cores usage. We can see below all kernels’ time spent on GPU.
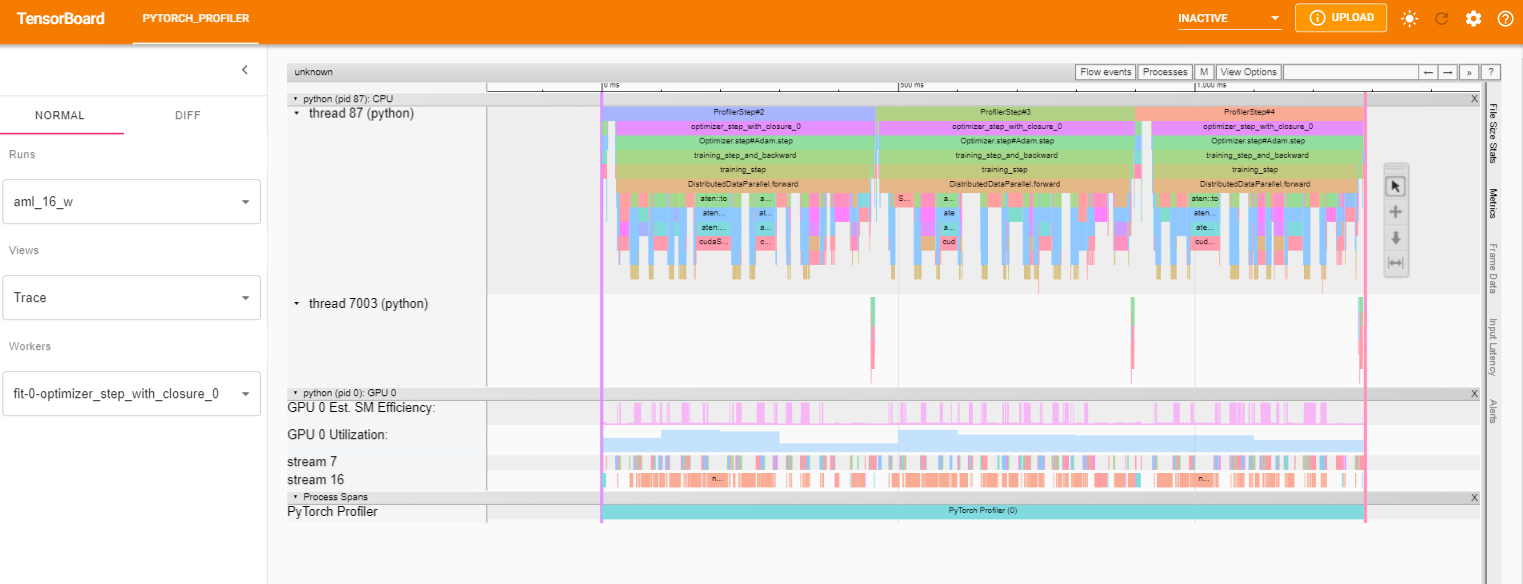
The trace view shows timeline of profiled operators and GPU kernels. You can select it to see details as below.
For more details on how to interpret and analyze these views, refer to the pytorch official documentation
Advanced profiling arguments
In some scenarios, you might be interested in profiling the memory usage by setting
profile_memory=True or any of these additional arguments.
You can specify additional profiling arguments by overriding
get_trainer_arguments
in your LightningContainer as shown below. Please make sure to specify your custom profiler under the
profiler key and properly set dirpath=self.outputs_folder/"profiler" so that the profiler’s outputs are saved in the
right output folder.
class YourCustomContainer(LightningContainer):
def __init__(custom_param: Any) -> None:
self.custom_param = custom_param
def get_trainer_arguments(self) -> Dict[str, Any]:
return {"profiler": PyTorchProfiler(dirpath=self.outputs_folder/"profiler", with_memory=True, with_stack=True)}
The profiler will record all memory allocation/release events and allocator’s internal state during profiling. The memory view consists of three components as shown in the following.
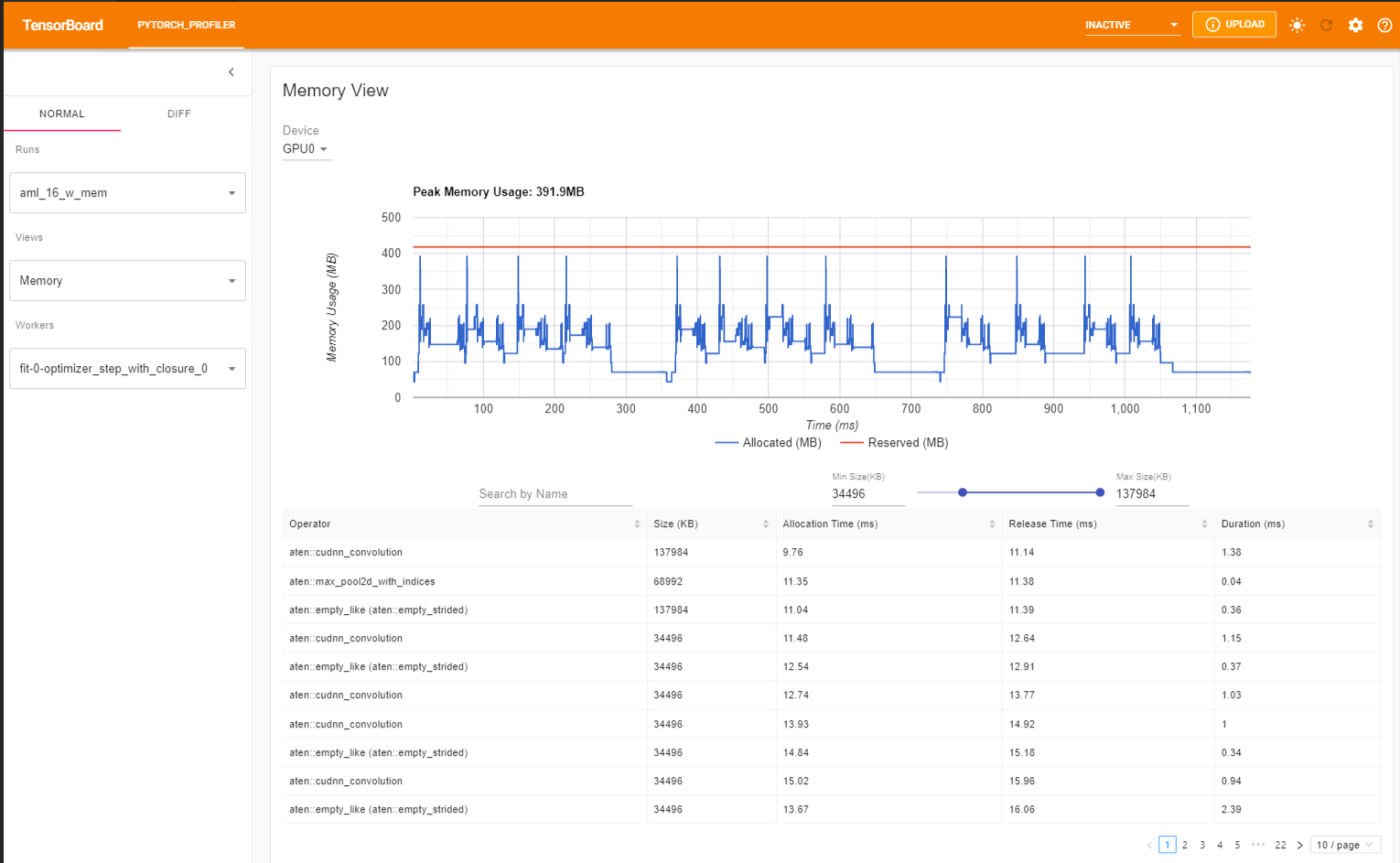
Finally, the plugin also supports distributed view on profiling DDP with NCCL/GLOO as backend.