Pre-training of an image encoder using self-supervised learning
Often in histopathology, we only have access to weak labels, e.g., a single label for an entire Whole Slide Image (WSI). However, papers like DeepSmiles show that we can use unlabeled tiles from WSI to pre-train an image encoder using Self-Supervised Learning (SSL). In hi-ml, we have implemented two popular self-supervised learning methods SimCLR and BYOL. We will use the TCGA-CRCk dataset, as seen in Kather et al. 2019, the dataset comes with binary WSI labels (microsatellite stable or instable). We will use the TCGA-CRCk dataset as an example to show how to set up SSL training in hi-ml. If you want to use your own dataset, you will find instructions at the end of this section.
Example: Train an image encoder using SSL on the TCGA-CRCk locally
The TCGA-CRCk dataset consists of colorectal tumor tiles extracted from Formalin-Fixed, Paraffin-Embedded (FFPE) WSIs from the Cancer Genome Atlas (TCGA) with accompanying binarized MicroSatellite Instability (MSI) labels. In the case of TCGA-CRCk, the dataset is already tiled, i.e., the WSI are not available. In public_datasets.md you will find instructions on how to download and setup the TCGA-CRCk dataset.
To train an image encoder using SSL locally run this in the hi-ml-cpath folder, with the HimlHisto conda
enviroment activated:
python ../hi-ml/src/health_ml/runner.py --model SSL.CRCK_SimCLR
The model class
CRCK_SimCLR
is the config used to train a SSL model on TCGA-CRCk. It houses everything, e.g., the model, the dataset, checkpointing,
etc. Here, we need to define some important parameters:
The type of image encoder we want to train, the type of SSL (SimCLR or BYOL) we want to use, and the batch_size.
The dataset we want to use for training the image encoder and the linear model we only use for evaluation of the image encoder. In theory, they could be two different datasets.
Model checkpointing: We use PyTorch lightning checkpointing. Among others, we define the validation metric, where the
online_evaluatoris the same as thelinear_head. In the case of TCGA_CRCK, we use AUC ROC as the validation metric.
In the parent class of CRCK_SimCLR, HistoSSLContainer the data augmentations are defined. Data augmentation
is one of the most important components of SSL training. Currently, we have hardcoded the data augmentation used in the
SimCLR paper. These are the following:
While not optimized for WSI we observe good performance using these augmentations. The data augmentations are wrapped by
DualViewTransformWrapper
to return two augmented versions per tile, as required by the majority of SSL methods.
Train on Azure
In the case of SimCLR, the effective batch_size (batch_size * GPU) should be as big as possible. The SSL models in hi-ml natively supports distributed training using multiple GPUs. We recommend using 8 GPUs for running the SimCLR model on the TCGA-CRCk dataset. Assuming you are using a total of 8 GPUs (e.g. 1 node with 8 GPUs or 2 nodes with 4 GPUs) in Azure you can start training with the following command in the repository root folder:
python hi-ml/src/health_ml/runner.py --model SSL.CRCK_SimCLR --cluster CLUSTER_NAME --conda_env hi-ml-cpath/environment.yml
A SimCLR run with 200 epochs, 8 GPUs, and a batch size of 48 (per GPU) takes about 6 hours. On Azure we use Standard_ND40rs_v2 (40 cores, 672 GB RAM, 2900 GB disk, 8 x NVIDIA Tesla V100).
Let’s have a look at the training behavior.
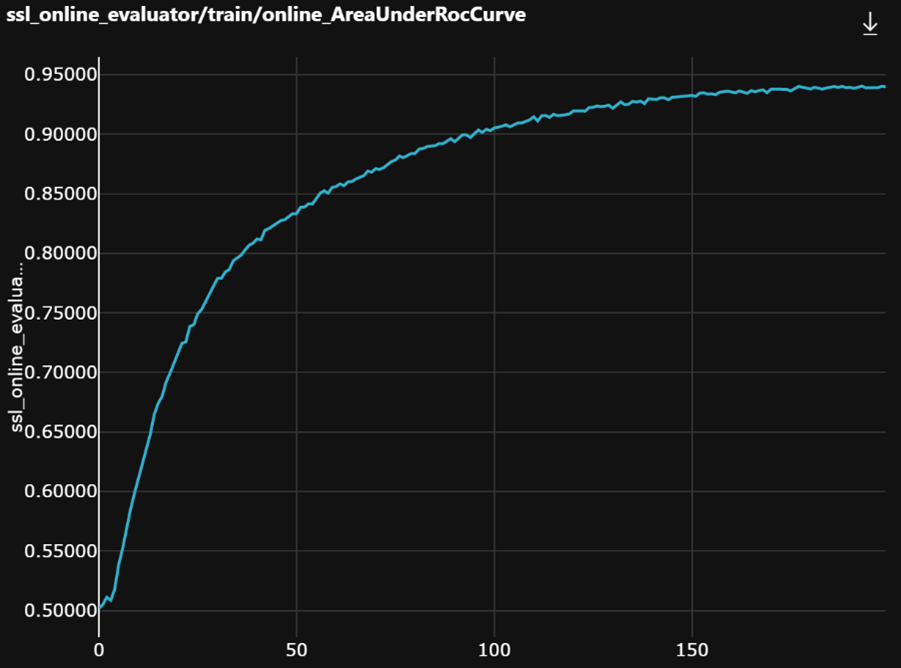
As mentioned previously, using the WSI label for each tile of the same slide and a linear head on the outputs of the image encoder to monitor training works quite well. We see a smooth and steady increase of the validation metric.
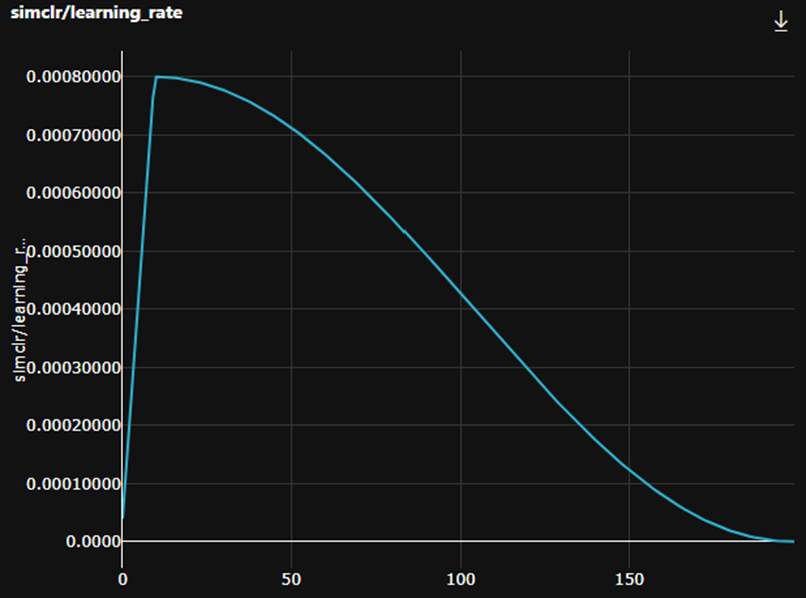
In addition, we are using a cosine learning rate schedule with a fixed warm up of 10 epochs. Note: The SSL code in hi-ml automatically scales the learning rate to the number of GPUs used during training, as described here.
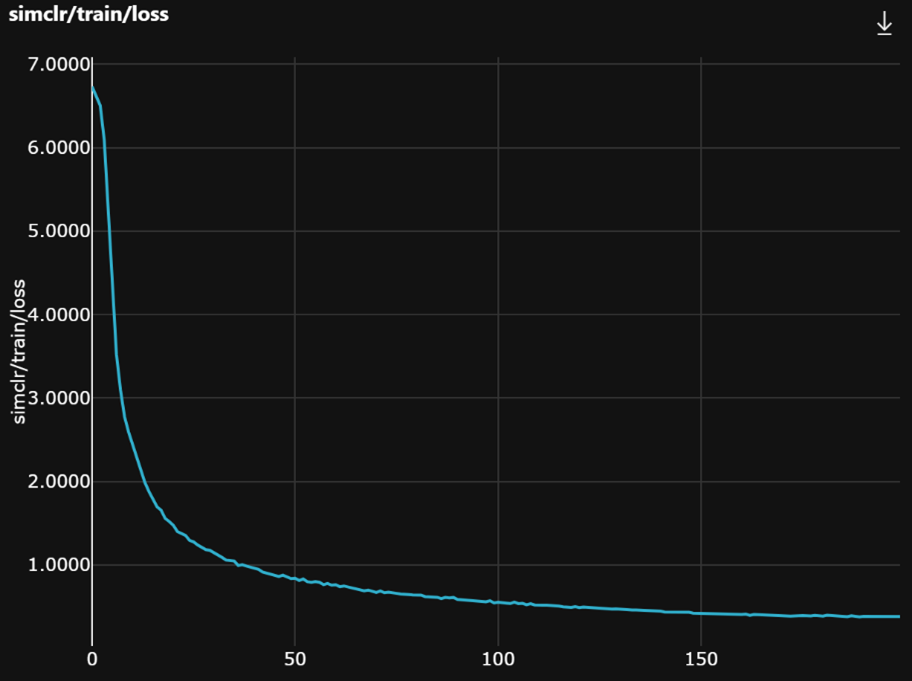
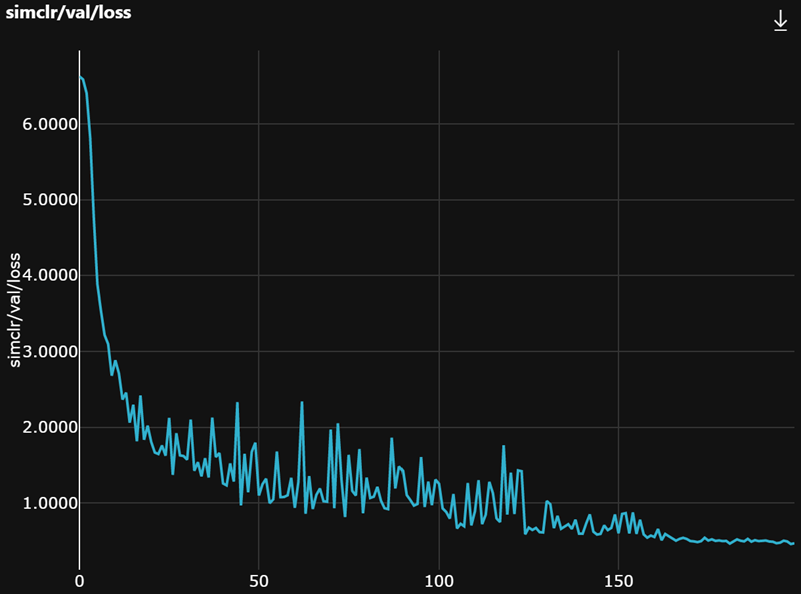
Last, the training and validation loss curves are expected to look like this.
After training, we can use the pre-trained image encoder on downstream tasks like microsatellite stable/instable
prediction on TCGA-CRCk. You only have to specify the path to the checkpoint of the SSL image encoder in the setup
function of
DeepSMILECrck.
Using your own dataset
For scripts that help you tile your own dataset please see
histopathology/preprocessing/tiling.py.
In the case of TCGA-CRCk, the dataset is already tiled.
TcgaCrck_TilesDataset
is a child of
TilesDataset.
For a
TilesDataset
we assume that each tile has a unique tile index and a label. Since we assume that we are working with weakly labelled
WSI we do not have access to the real tile labels. However, we found that monitoring the SSL training using the slide
label for each tile works sufficiently well. I.e., if the WSI has a positive label then every tile from the WSI has a
positive label. Last, the unique index for each tile is used to make sure we don’t use twice the same tile in one
training epoch during SSL training.
Subsequently, the TCGA-CRCk dataset is wrapped in
TcgaCrck_TilesDatasetReturnImageLabel.
Here the data augmentations are applied and the __getitem__ method is defined.
The dataset is then wrapped one last time in
TcgaCrck_TilesDatasetWithReturnIndex,
where we inherit the ability to return the tile index from
DatasetWithReturnIndex.